My personal list of resources and samples related to working with Databricks. Opinions are my own and not the views of my employer.
- By Cloud: AWS | Azure | Google Cloud
- By Industry: FSI | Healthcare | Media & Entertainment | Retail and CPG
- dbdemos.ai
- Demo Hub: access ready-to-run Notebooks that walk you through common workflows and use cases on Databricks
▶️ Data + AI Summit (DAIS) recordings: 2023 | 2022- Weekly "Ask Databricks" Live Sessions. You can also catch replays on Databricks' and Advancing Analytics' YouTube channels
- What's coming page: provides an overview of what's coming in near future releases, helping you plan ahead of time
- Free Live Onboarding Training: no-cost, role-based onboarding training, multiple times a day across key geographic regions for Databricks customers, partners, as well as the general public
- Free half-day live training classes
- Customer Academy: all your self-paced training and certification needs in one place
- Paid Instructor-Lead Training (ILT) Training
- Request private training
- Databricks Community: community forum
- Enroll in our New Expert-Led Large Language Models (LLMs) Courses on edX starting Jun 8! Master Large Language Models with expert guidance, hands-on learning, and insights from industry pioneers. Explore cutting-edge techniques like prompt engineering, embeddings, vector databases, and model tuning. Learn from luminaries like Stanford Professor & Databricks Co-Founder Matei Zaharia and the creators of Dolly. Access free course materials to audit and elevate your LLM expertise. Consistent with our goal of keeping things open, course materials are free for anyone to audit. Enroll today
- Databricks New Features and Capabilities: this can help you come up to speed with the latest over the last 6-12 months
- Databricks Onboarding Series
- Databricks Lakehouse Fundamentals
- Generative AI Fundamentals
- Azure Platform Architect
- GCP Platform Architect
- Data Engineering Practitioner (also prepares you for certification)
- Machine Learning Practitioner (also prepares you for certification)
- Full catalog
- Short tutorials
- Azure Databricks: Platform release notes | Runtime release notes | Databricks SQL release notes
- 📄 Databricks Academy lab notebooks
- 📄 Databricks Industry Solutions notebooks
- 📄 Databricks ML examples with detailed Notebooks on how to work with OSS LLMs (e.g.
Llama-2-*,mpt-*) using MLflow in Databricks - 📄 LLM GPU serving examples
- Notebook gallery
- Try the Community Edition for free (no Databricks or AWS costs are incurred by you)
- Databricks Community Q&A
- Stack Overflow: databricks, apache-spark, psypark, apache-spark-sql
- User Groups: 🇦🇺 Sydney | Melbourne
- Submit feature requests (ideas) through the Ideas Portal
- CIO Vision 2025 report in conjunction with MIT
- 2023 State of Data + AI report
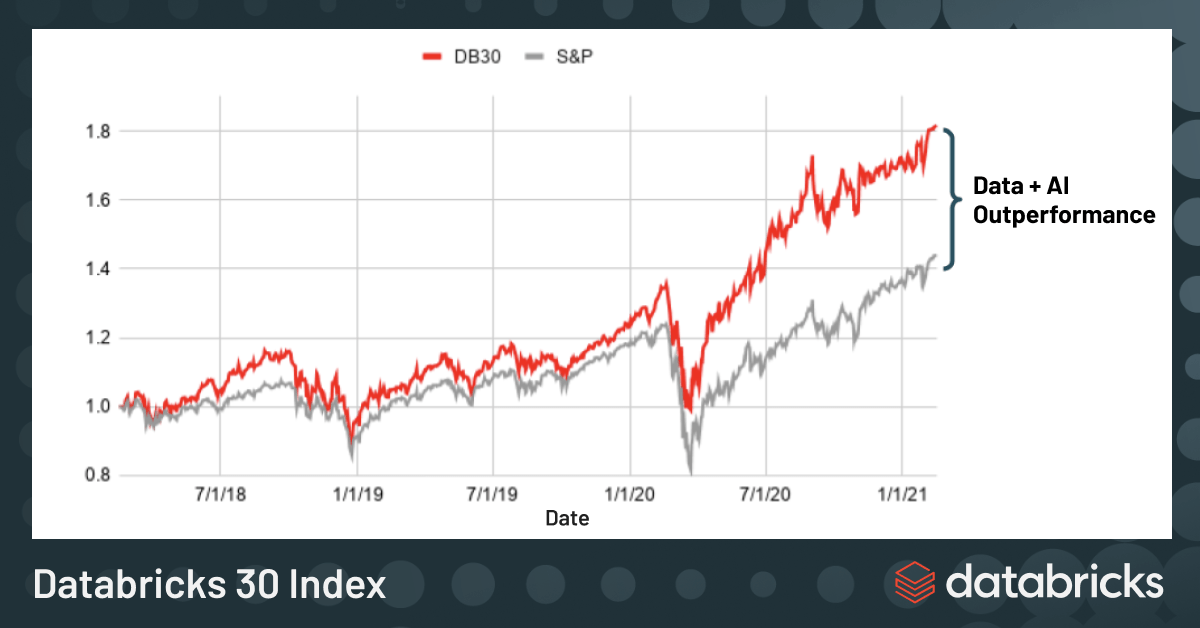
- Databricks 30 Index: (March 2021) The Databricks 30 is an equal-weight price index composed of 5 marquee customers each across Retail/Consumer Products, Financial Services, Healthcare, Media/Entertainment, Manufacturing/Logistics, in addition to 5 strategic partners
- Forrester Total Economic Impact™ Study (April 2020)
- Customers averaged nearly $29 million in total economic impact and ROI over three years totaled 417%, driven by:
- 5% increase in revenue by unlocking new data science opportunities
- $11 million savings from retiring on-prem infrastructure and legacy licenses
- Faster time to market due to improved data team productivity of up to 25%
- Customers averaged nearly $29 million in total economic impact and ROI over three years totaled 417%, driven by:
- Why we bet our business on Databricks, and why you should too
- Founding member of the Data Cloud Alliance: "Commitment to accelerating adoption across industries through common industry data models, open standards, processes, and end-to-end integrated products and solutions"

- Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics Research paper from the 11th Annual Conference on Innovative Data Systems Research (CIDR ’21), January 11–15, 2021. My annotated version
- Don’t Let a Cloud Data Warehouse Bottleneck your Machine Learning
- 6 Guiding Principles to Build an Effective Data Lakehouse
- A data architecture pattern to maximize the value of the Lakehouse
- Data Warehousing Modeling Techniques and Their Implementation on the Databricks Lakehouse Platform
- Five Simple Steps for Implementing a Star Schema in Databricks With Delta Lake
- Databricks Lakehouse and Data Mesh, (Part 1) (Part 2)
- Dimensional modeling implementation on the modern lakehouse using Delta Live Tables: covers SCD1 & SCD2, PK/FK constraints, IDENTITY columns, and constraints (📄 Notebook)
- Prescriptive Guidance for Implementing a Data Vault Model on the Databricks Lakehouse Platform
- Architecting MLOps on the Lakehouse
- Leveraging Delta Across Teams at McGraw Hill (source code to automate the Databricks to Athena manifest based integration)
- Data Modeling using erwin on Databricks
- Multi-cloud Architecture for Portable Data and AI Processing in Financial Services: a useful blueprint for owning a reliable and governed multi-cloud data architecture. Although this article is focused on the financial services industry, it is relevant for any organisations with data footprints across clouds


- Databricks Workspace Administration – Best Practices for Account, Workspace and Metastore Admins
- Functional Workspace Organization on Databricks (Databricks Admin Essentials: Blog 1/5)
- Monitoring Your Databricks Lakehouse Platform with Audit Logs (Databricks Admin Essentials: Blog 2/5) (Notebook)
- Serving Up a Primer for Unity Catalog Onboarding (Databricks Admin Essentials)
- Intelligently Balance Cost Optimization & Reliability on Databricks
- Best Practices for Cost Management on Databricks
- Cluster Policy Primer: Cluster policies allow you to enforce security and cost controls on new clusters. This post walks you through what cluster policies are and how to design them for your Workspaces
- Cost-conscious R&D in the Cloud that Data Scientists Will Love
- Databricks cost management at Coinbase: outlines the cost management strategy implemented at Coinbase for Databricks applications, including the launch of a cost insights platform and quota enforcement platform
- How We Cut Our Databricks Costs by 50% (AWS)
- Disaster Recovery Overview, Strategies, and Assessment (Part 1 of DR series) (Part 2) (Part 3)
- How illimity Bank Built a Disaster Recovery Strategy on the Lakehouse - DR strategy, Terraform management, data & metadata replication strategy
- Security and Trust Center
- Databricks Bug Bounty Program (example of bug bounty response: Admin Isolation on Shared Clusters)
- Commitment to Responsible AI
- Security best practices including comprehensive checklists for GCP, Azure, and AWS
- Security Analysis Tool (SAT): 📄 GitHub repo,
▶️ Setup instructions - GxP Best Practices Whitepaper: GxP stands for "Good x Practices" and the variable
xrefers to a specific discipline, such as clinical, manufacturing or laboratory. The goal of GxP compliance is to ensure that regulated industries have a process that runs reliably, can survive failures and human error, and meets global traceability, accountability and data integrity requirements. No matter what industry you operate in, I believe these are solid practices to align with - Audit Log schema
- Admin Isolation on Shared Clusters
- Scanning for Arbitrary Code in Databricks Workspace With Improved Search and Audit Logs
- Monitoring Notebook Command Logs With Static Analysis Tools (📄 Notebooks)
- Protecting Your Compute Resources From Bitcoin Miners With a Data Lakehouse
- An example of using the
MASK()(available in DBR 12.2+) function for easy data masking - How Databricks restricts third party libraries in JVM compute platforms
- Building the Trusted Research Environment with Azure Databricks
- How PII scanning is done at Seek using Presidio and Unity Catalog
- Identifying and Tagging PII data with Unity Catalog
- Serving Up a Primer for Unity Catalog Onboarding (Databricks Admin Essentials)
- 📕 Unity Catalog example Notebook
- The Hitchhiker's Guide to data privilege model and access control in Unity Catalog
- How Terraform can enable Unity Catalog deployment at scale for different governance models
- Terraform scripts
▶️ How to Sync nested AD groups to Databricks- Export lineage via API example
- How to Seamlessly Upgrade Your Hive Metastore Objects to the Unity Catalog Metastore Using SYNC (📄 notebook)
- Simplify Access Policy Management With Privilege Inheritance in Unity Catalog
- How Gemini Built a Cryptocurrency Analytics Platform Using Lakehouse for Financial Services: "The core lakehouse foundation and features resonated with the team as an efficient way to build the data platform"

- Apache Spark and Photon Receive SIGMOD Awards
- Apache Spark wins 2022 ACM SIGMOD Systems Award! “Apache Spark is an innovative, widely-used, open-source, unified data processing system encompassing relational, streaming, and machine-learning workloads.”
- GitHub: Apache Spark
- Learning Spark (2nd Edition) (book)
- Learning Spark code samples
- Photon: A Fast Query Engine for Lakehouse Systems: SIGMOD 2022 Paper
- Apache Spark and Photon Receive SIGMOD Awards
- List of expressions supported by Photon
▶️ Advancing Spark - The Photon Whitepaper- How DuPont achieved 11x latency reduction and 4x cost reduction with Photon

- Newsletter: Last Week in a Byte
- Roadmap
- Releases
- Release Milestones
- Delta Transactional Log Protocol
- 📄 Delta Lake VLDB paper (my annotated version)
- 📘 Delta Lake: The Definitive Guide (O'Reilly) (access free preview | PDF direct link)
- Diving Into Delta Lake: Unpacking The Transaction Log
- Diving Into Delta Lake: Schema Enforcement & Evolution
- Diving Into Delta Lake: DML Internals (Update, Delete, Merge)
- Processing Petabytes of Data in Seconds with Databricks Delta
- Top 5 Reasons to Convert Your Cloud Data Lake to a Delta Lake
- How to Rollback a Delta Lake Table to a Previous Version with Restore
- Exploring Delta Lake’s
ZORDERand Performance - Idempotent Writes to Delta Lake Tables
- hydro 💧: a collection of Python-based Apache Spark and Delta Lake extensions
- The Ubiquity of Delta Standalone: a JVM library that can be used to read and write Delta Lake tables. Unlike Delta Lake Core, this project does not use Spark to read or write tables and has only a few transitive dependencies. It can be used by any application (e.g. Power BI) that cannot use a Spark cluster. The project allows developers to build a Delta connector for an external processing engine following the Delta protocol without using a manifest file.
- GitHub repository
- Release Milestones
▶️ Databricks Delta Sharing demo▶️ PowerBI and Delta Sharing▶️ Advancing Spark - Delta Sharing and Excel (via PowerBI)- Arcuate: Machine Learning Model Exchange With Delta Sharing and MLflow
- Java connector(supporting blog post)
- Security Best Practices for Delta Sharing
- Using Structured Streaming with Delta Sharing in Unity Catalog
- Cost Effective and Secure Data Sharing: The Advantages of Leveraging Data Partitions for Sharing Large Datasets
- Using Delta Sharing to Accelerate Insights with Nasdaq’s Digital Assets Market Data: an example of analysing Nasdaq data shared via Delta Sharing (sample 📕 Notebooks)
- How Delta Sharing Helped Rearc Simplify Data Sharing and Maximize the Business Value of Its Data: With over 450+ open curated data products available across different sectors, Rearc's cross-industry catalog of datasets is one of the largest available today (Rearc data library)
- Auto-Loader
- Easy Ingestion to Lakehouse With
COPY INTO - dbt (GitHub)
▶️ dbt Projects Integration in Databricks Workflows- Best Practices for Super Powering Your dbt Project on Databricks
- Build Data and ML Pipelines More Easily With Databricks and Apache Airflow
- Ingesting emails (IMAP)
- Latency goes subsecond in Apache Spark Structured Streaming: progress has been made on Project Lightspeed, and the introduction of async offset management shows a 3x improvement in stream latency
- Real-Time Insights: The Top Three Reasons Why Customers Love Data Streaming with Databricks
- Simplifying Streaming Data Ingestion into Delta Lake
- Streaming in Production: Collected Best Practices - Part 1, Part 2
- Speed Up Streaming Queries With Asynchronous State Checkpointing
- Scalable Spark Structured Streaming for REST API Destinations: How to use Spark Structured Streaming's foreachBatch to scalably publish data to REST APIs
- Feature Deep Dive: Watermarking in Apache Spark Structured Streaming
- Python Arbitrary Stateful Processing in Structured Streaming
- Monitoring streaming queries (PySpark | Scala)
- Using Spark Structured Streaming to Scale Your Analytics
- State Rebalancing in Structured Streaming
▶️ Streaming data into the Lakehouse- Simplifying Streaming Data Ingestion into Delta Lake
- Enhanced Fan-Out for Kinesis on Databricks
- Roadmap: Project Lightspeed: Faster and Simpler Stream Processing With Apache Spark
- Debugging using the Structured Streaming UI (Spark docs)
- Confluent Streaming for Databricks: Build Scalable Real-time Applications on the Lakehouse (Part I) (Part II)

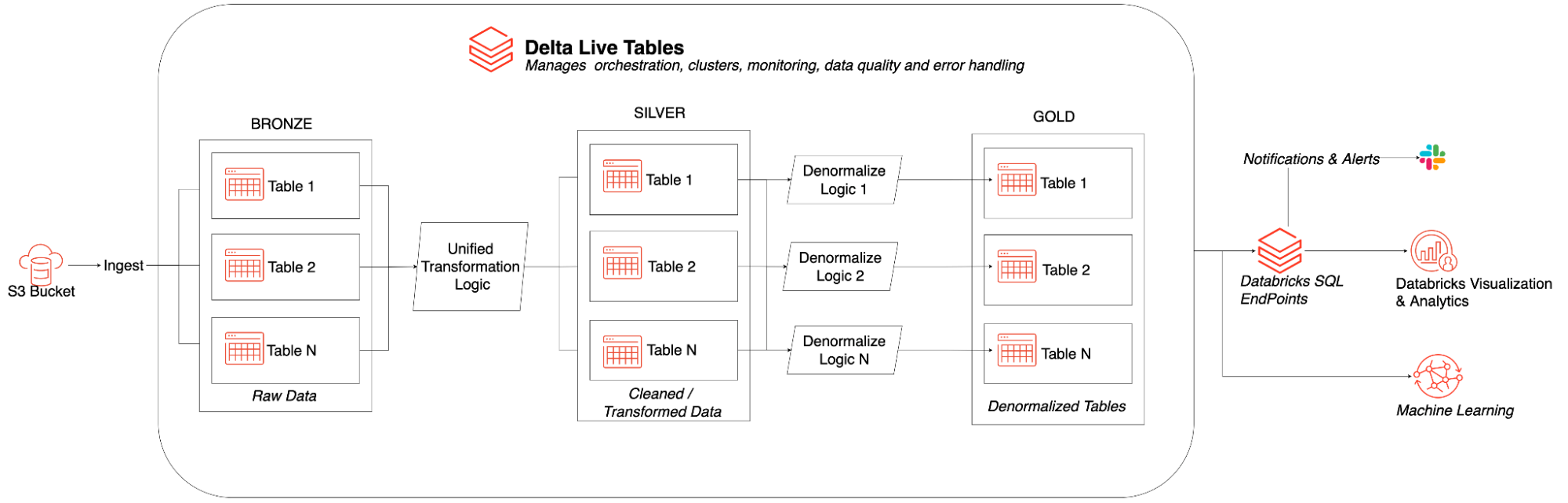
- Delta Live Tables Notebooks
- How We Performed ETL on One Billion Records For Under $1 With Delta Live Tables (DLT): learn how to own a $1 terabyte scale incremental pipeline that includes varied data structures (CSV & XML), CDC with SCD Type II, modeling, and data quality enforcements, while all along utilising spot compute. Check out the DLT definitions in this GitHub repo. What stood out for me were:
- 2x speedup due to DLT making efficient compute decisions
- Data quality checks exposed data errors others hadn't picked up before (needle in a haystack of 1.5B records)
- Easy SCD Type II logic handling
- Processing data simultaneously from multiple streaming platforms using Delta Live Tables: walkthrough of simultaneously ingesting and transforming streams across Azure Event Hubs, Kafka, and Kinesis
- Dimensional modeling implementation on the modern lakehouse using Delta Live Tables: covers SCD1 & SCD2, PK/FK constraints, IDENTITY columns, and constraints (📄 Notebook)
- Data Vault Best practice & Implementation on the Lakehouse
- Track health and fitness goals with Apple Healthkit and Databricks: great walkthrough of building out health insights using a metadata-driven approach with Delta Live Tables for ETL (GitHub repo)
- Deloitte’s Guide to Declarative Data Pipelines With Delta Live Tables (Whitepaper)
- Build a Customer 360 Solution with Fivetran and Delta Live Tables - includes SCD2 example
- Simplifying Change Data Capture With Databricks Delta Live Tables
- Delivering Real-Time Data to Retailers with Delta Live Tables (fully documented notebooks)
- Building ETL pipelines for the cybersecurity lakehouse with Delta Live Tables: ingest & evaluate AWS CloudTrail & VPC Flow logs (accompanying notebooks: CloudTrail DLT pipeline, VPC Flow Logs DLT pipeline, Zeek DLT pipeline)
- Low-latency Streaming Data Pipelines with Delta Live Tables and Apache Kafka
▶️ Apache Kafka and Delta Live Tables- How I Built A Streaming Analytics App With SQL and Delta Live Tables: accompanying repo
- How Uplift built CDC and Multiplexing data pipelines with Databricks Delta Live Tables
- Near Real-Time Anomaly Detection with Delta Live Tables and Databricks Machine Learning
- How Collective Health uses Delta Live Tables and Structured Streaming for Data Integration: informative walkthrough of how they use DLT to perform quality control on data shared by partners while also managing schema evolution
- How Audantic Uses Databricks Delta Live Tables to Increase Productivity for Real Estate Market Segments

- SQL CLI: run SQL queries on your SQL endpoints from your terminal. From the command line, you get productivity features such as suggestions and syntax highlighting
- sqlparse: open source library for formatting and analysing SQL strings
- Databricks Workflows Through Terraform: Part I, Part II
- Why We Migrated From Apache Airflow to Databricks Workflows at YipitData
- Save Time and Money on Data and ML Workflows With “Repair and Rerun”
- VS Code extension (short
▶️ video) - Using Databricks SQL in VSCode
- Use an IDE with Databricks
- Debug your code and notebooks by using Visual Studio Code
- Interactive debugging with Databricks Connect: developers can step through their code and inspect variables in real time. Databricks Connect enables running Spark code on remote clusters from the IDE, thereby enabling code step-through while debugging
- Support for
ipynbnotebooks - Support for
dbutilsand Spark SQL
▶️ Databricks Connect v2 Quickstart- Spark Connect Available in Apache Spark 3.4: Run Spark Applications Everywhere: write PySpark in any environment and have your instructions processed in a remote Spark environment (e.g. Databricks cluster)!
databricks-connectsupports Spark Connect when using DBR13.0+. This simplifies client application development, mitigates memory contention on the Spark driver, separates dependency management for client applications, allows independent client and server upgrades, provides step-through IDE debugging, and thin client logging and metrics! - Use Databricks from anywhere with Databricks Connect v2: use the power of Databricks from any application running anywhere. It is also included in our VS Code extension enabling built-in debugging of code on Databricks! Here's a sample application
▶️ Databricks Connect + Spark Connect: How you can build on Spark from anywhere: "Databricks Connect v2 leverages Spark Connect so you can connect to your Spark clusters within Databricks"- Software engineering best practices for notebooks (accompanying notebooks) (accompanying notebooks)
- Build Reliable Production Data and ML Pipelines With Git Support for Databricks Workflows (📄 notebooks)
- Run SQL Queries on Databricks From Visual Studio Code: makes life easy if you use the SQLTools extension and want to iterate on your SQL logic while in your local environment (e.g. while debugging
dbtmodel logic) (download Databricks driver for SQLTools


- 30+ reusable Terraform modules to provision your Databricks Lakehouse platform: the newly released Terraform Registry modules for Databricks provides 30+ reusable Terraform modules and examples to provision your Databricks Lakehouse platform. I've found this useful for exploring best practices and speeding up Terraform development
- Spark test suite (Scala)
- Introduction to Databricks SQL: a good walkthrough by one of our partners on the capabilities of Databricks SQL
- Understanding Caching in Databricks SQL: UI, Result, and Disk Caches
- Actioning Customer Reviews at Scale with Databricks SQL AI Functions: bring meaning to unstructured data using the simplicity of SQL and GPT-3.5
- What’s New With SQL User-Defined Functions 2023-01-18

- Comprehensive Guide to Optimize Databricks, Spark and Delta Lake Workloads: a new guide walking you through all the possible ways to tune your workloads for ⚡️ performance and 💰 cost
- Streaming in Production: Collected Best Practices - Part 1, Part 2
- 10 Best Practices for writing SQL in Databricks
- Comprehensive Guide to Optimize Databricks, Spark and Delta Lake Workloads
- Delta Lake best practices
- Optimize performance with file management
- Make Your Data Lakehouse Run, Faster With Delta Lake 1.1
- Get to Know Your Queries With the New Databricks SQL Query Profile
- Top 5 Performance Tips
- Memory Profiling in PySpark
- How to consistently get the best performance from star schema databases
- Delta – Best Practices for Managing Performance by partner Daimlinc
- Introducing Ingestion Time Clustering with Databricks SQL and Databricks Runtime 11.2: 19x faster query performance out-of-the-box. Write optimization, ensuring clustering is always maintained by ingestion time → significant query performance gains
- Faster insights With Databricks Photon Using AWS i4i Instances With the Latest Intel Ice Lake Scalable Processors: Up to 2.5x price/performance benefits and 5.3x speed up!
- Improved Performance and Value With Databricks Photon and Azure Lasv3 Instances Using AMD 3rd Gen EPYC™ 7763v Processors: Up to 2.5x price/performance benefits and 5.3x speed up!
- Reduce Time to Decision With the Databricks Lakehouse Platform and Latest Intel 3rd Gen Xeon Scalable Processors:
"By enabling Databricks Photon and using Intel’s 3rd Gen Xeon Scalable processors, without making any code modifications, we were able to save ⅔ of the costs on our TPC-DS benchmark at 10TB and run 6.7 times quicker"


- Delta Lake orders the data in the Parquet files to make range selection on object storage more efficient
- Limit the number of columns in the Z-Order to the best 1-4
ANALYZE TABLE db_name.table_name COMPUTE STATISTICS FOR ALL COLUMNS
- Utilised for Adaptive Query Execution (AQE), re-optimisations that occur during query execution
- 3 major features of AQE
- Coalescing post-shuffle partitions (combine small partitions into reasonably sized partitions)
- Converting sort-merge joins to broadcast hash joins
- Skew join optimisation by splitting (and replicating if needed) skewed tasks into roughly evenly sized tasks
- Dynamically detects and propagates empty relations
ANALYZE TABLEcollects table statistics that allows AQE to know which plan to choose for you
- Architecting MLOps on the Lakehouse
- MLOps at Walgreens Boots Alliance With Databricks Lakehouse Platform - experiences with preview of MLOps Stack
▶️ MLflow YouTube channel- Cross-version Testing in MLflow: MLflow integrates with several popular ML frameworks. See how the Databricks Engineering team proactively adapt MLflow and third-party libraries to prevent against breaking changes
- Model Evaluation in MLflow
- Synthetic Data for Better Machine Learning: a guide to using Synthetic Data Vault (SDV) with MLflow to generate synthetic data, that reflects real-world data, for better models or safer data sharing between teams
- How (Not) To Scale Deep Learning in 6 Easy Steps
- PyTorch on Databricks - Introducing the Spark PyTorch Distributor: You can now easily perform distributed PyTorch training with PySpark and Databricks! (sample 📕Notebook
- Accelerating Your Deep Learning with PyTorch Lightning on Databricks
- Ray support on Databricks and Apache Spark Clusters
▶️ Scaling Deep Learning on Databricks- Rapid NLP Development With Databricks, Delta, and Transformers
- Mitigating Bias in Machine Learning With SHAP and Fairlearn(accompanying 📄 notebook)
- Parallel ML: How Compass Built a Framework for Training Many Machine Learning Models
- LLM Model Recommendations: we often get asked what are the best OSS LLM models to use for which use case. This frequently-updated matrix is a handy reference to identify the right models by use case and depending on whether you are seeking quality-, balanced-, or speed-optimised models
- GitHub repo with detailed Notebooks on how to work with OSS LLMs (e.g.
Llama-2-*,mpt-*) using MLflow in Databricks - 📄 LLM GPU serving examples
- Actioning Customer Reviews at Scale with Databricks SQL AI Functions: bring meaning to unstructured data using the simplicity of SQL and GPT-3.5
- Tutorial: Connecting Databricks’ DBRX LLM to a Power BI report
- Implementing LLM Guardrails for Safe and Responsible Generative AI Deployment
- Getting Started with Personalization through Propensity Scoring (accompanying notebooks)
- Building an End-to-End No Code Pipeline with Databricks
- Using MLflow to deploy Graph Neural Networks for Monitoring Supply Chain Risk
- Predicting the 2022 World Cup with no-code data science and machine learning: covers
bamboolib+ AutoML + serverless inference (repo) - Fine-Tuning Large Language Models with Hugging Face and DeepSpeed
- How Outreach Productionizes PyTorch-based Hugging Face Transformers for NLP
- Getting started with NLP using Hugging Face transformers pipelines
- Rapid NLP Development With Databricks, Delta, and Transformers: Hugging Face, BERT
- GPU-accelerated Sentiment Analysis Using Pytorch and Hugging Face on Databricks
▶️ Streaming Data with Twitter, Delta Live Tables, Databricks Workflows, and Hugging Face- Quantifying uncertainty with Tensorflow Probability
- How Corning Built End-to-end ML on Databricks Lakehouse Platform (
▶️ AWS re:Invent 2022 talk) - Scale Vision Transformers (ViT) on the Databricks Lakehouse Platform with Spark NLP: Spark NLP's latest release includes support for vision transformers. This guide walks through scaling ViTs on Databricks
- Mosaic: a Databricks Labs extension to the Apache Spark framework that allows easy and fast processing of very large geospatial datasets
- GitHub: Mosaic
- Building a Geospatial Lakehouse, Part 1
- Building a Geospatial Lakehouse, Part 2: includes downloadable notebooks
- High Scale Geospatial Processing With Mosaic: writeup on the underlying philosophy behind Mosaic's design
- Building Geospatial Data Products
- Built-in H3 Expressions for Geospatial Processing and Analytics
- Supercharging H3 for Geospatial Analytics "In this blog, you will learn about the new expressions, performance benchmarks from our vectorized columnar implementation, and multiple approaches for point-in-polygon spatial joins using H3"
- Spatial Analytics at Any Scale With H3 and Photon: A Comparison of Discrete, Vector, and Hybrid Approaches
- How Thasos Optimized and Scaled Geospatial Workloads with Mosaic on Databricks: Thasos is an alternative data intelligence firm that transforms real-time location data from mobile phones into actionable business performance insights. To derive actionable insights from mobile phone ping data (a time series of points defined by a latitude and longitude pair), Thasos created, maintains and manages a vast collection of verified geofences
- ArcGIS GeoAnalytics Engine in Databricks


- Unsupervised Outlier Detection on Databricks utilising Databricks' new Kakapo package (which integrates the vast PyOD library of outlier detection algorithms with MLFlow for tracking and packaging of models and Hyperopt for exploring vast, complex and heterogeneous search spaces) (sample 📕 Notebook)
- Build your own Chatbot: walks through indexing documents, generating embeddings (using OpenAI embeddings), persisting embeddings in a vector store (FAISS), creating a Q&A flow (using Langchain), persisting the model in MLflow registry, and serving the model for your applications (Accompanying blog post)
- Customer Entity Resolution (Solution Accelerator page | Notebooks)
- The Emergence of the Composable Customer Data Platform (whitepaper)
- Hunting for IOCs Without Knowing Table Names or Field Labels
- Hunting Anomalous Connections and Infrastructure With TLS Certificates: TLS hashes as a source for the cybersecurity threat hunting program
- Cybersecurity in the Era of Multiple Clouds and Regions
- Building ETL pipelines for the cybersecurity lakehouse with Delta Live Tables: ingest & evaluate AWS CloudTrail & VPC Flow logs (accompanying notebooks: CloudTrail DLT pipeline, VPC Flow Logs DLT pipeline, Zeek DLT pipeline)
- Accelerating SIEM Migrations With the SPL to PySpark Transpiler
- Learn how to connect Databricks to Okta to ingest System Logs, retain, and analyze for complete visibility using your Databricks Lakehouse Platform (accompanying notebooks)
- Streaming Windows Event Logs into the Cybersecurity Lakehouse (notebook)
- Building a Cybersecurity Lakehouse for CrowdStrike Falcon Events Part I, Part II, Part III
▶️ Vlogs on security engineering for big data and cybersecurity: by Lipyeow Lim, Technical Director, Cybersecurity GTM, Databricks
- Simplify entity resolution with Databricks Automated Record Connector (ARC) ARC abstracts away the complexity of utilising UK Ministry of Justice's Splink library for entity resolution. It determines the optimal set of blocking rules, comparisons, and deterministic rules (GitHub repo)
- Solution Accelerator: Automated Analysis of Product Reviews Using Large Language Models (LLMs)(📕 Notebooks)
- Real-Time Propensity Estimation to Drive Online Sales: real-time scoring of purchase intent doesn't have to be hard! This Solution Accelerator walks you through the end-to-end process of having your own real-time scoring model on Databricks. Check out the 📄 detailed notebooks that walk you through data preparation, ETL, model training with Feature Store, model registry, processing live events in streaming or batch, and deploying the model for real-time inference
- Enhancing the Amperity CDP with Personalized Product Recommendations: move identity resolution data easily between Amperity and Databricks using Amperity's Databricks Delta table destination connector (sample 📕 Notebook)
- Managing Complex Propensity Scoring Scenarios with Databricks(Notebooks| GitHub): a new Solution Accelerator to manage regular feature updates (utilising Feature Store) and periodic model re-training
- Enhancing Product Search with LLMs This example utilises Wayfair's annotation dataset (WANDS) to fine-tune a
SentenceTransformer('all-MiniLM-L12-v2')model, generate and store embeddings in a vector store (Chroma), register the model and embeddings in MLflow registry, and finally deploy the model for serving (accompanying blog post)
- Databricks Labs Data Generator: Python library for generating synthetic data within the Databricks environment using Spark. The generated data may be used for testing, benchmarking, demos, and many other uses.
- dbx: DataBricks CLI eXtensions - aka
dbxis a CLI tool for advanced Databricks jobs management
- Seamlessly Migrate Your Apache Parquet Data Lake to Delta Lake
- How To Migrate Your Oracle PL/SQL Code to Databricks Lakehouse Platform
- Australian Red Cross Lifeblood wins 2023 Data for Good Award: Red Cross are able to attract more donations and strengthen community bonds through initiatives that span granular forecasting, real-time wait-time predictions, customer segmentation, and marketing attribution
- Monash University stands up 'lakehouse' in Databricks, Azure
- Australia's heavy vehicle regulator builds 'fatigue engine' to reduce truckie deaths
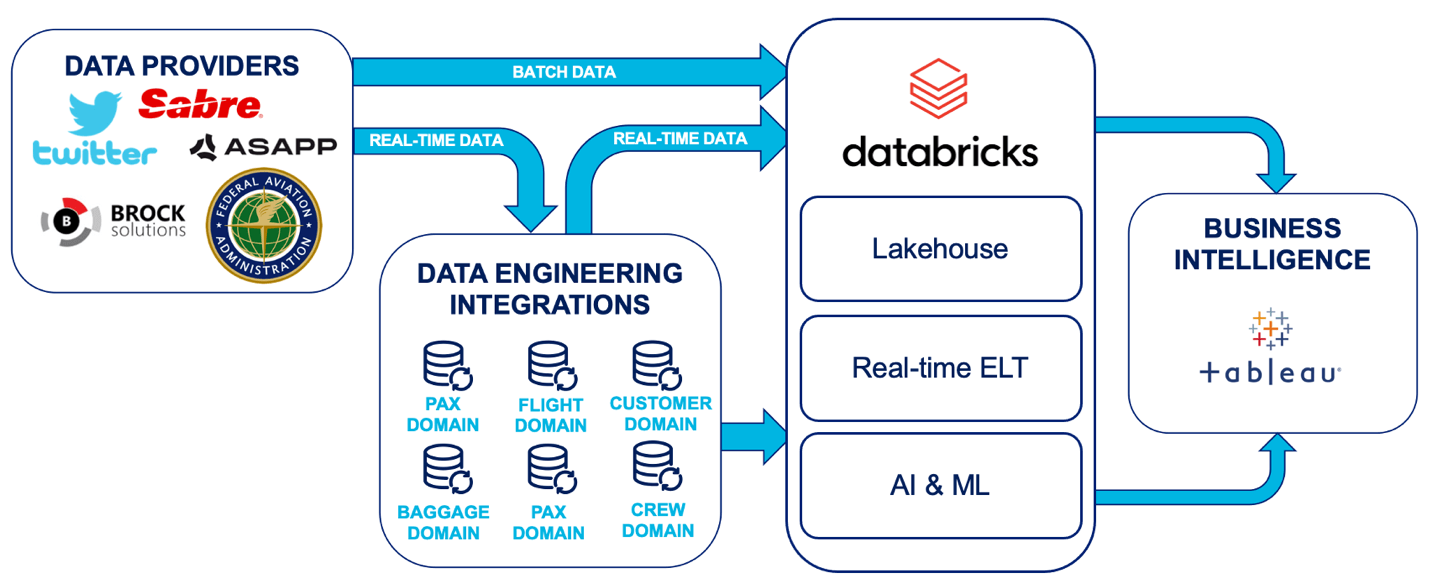
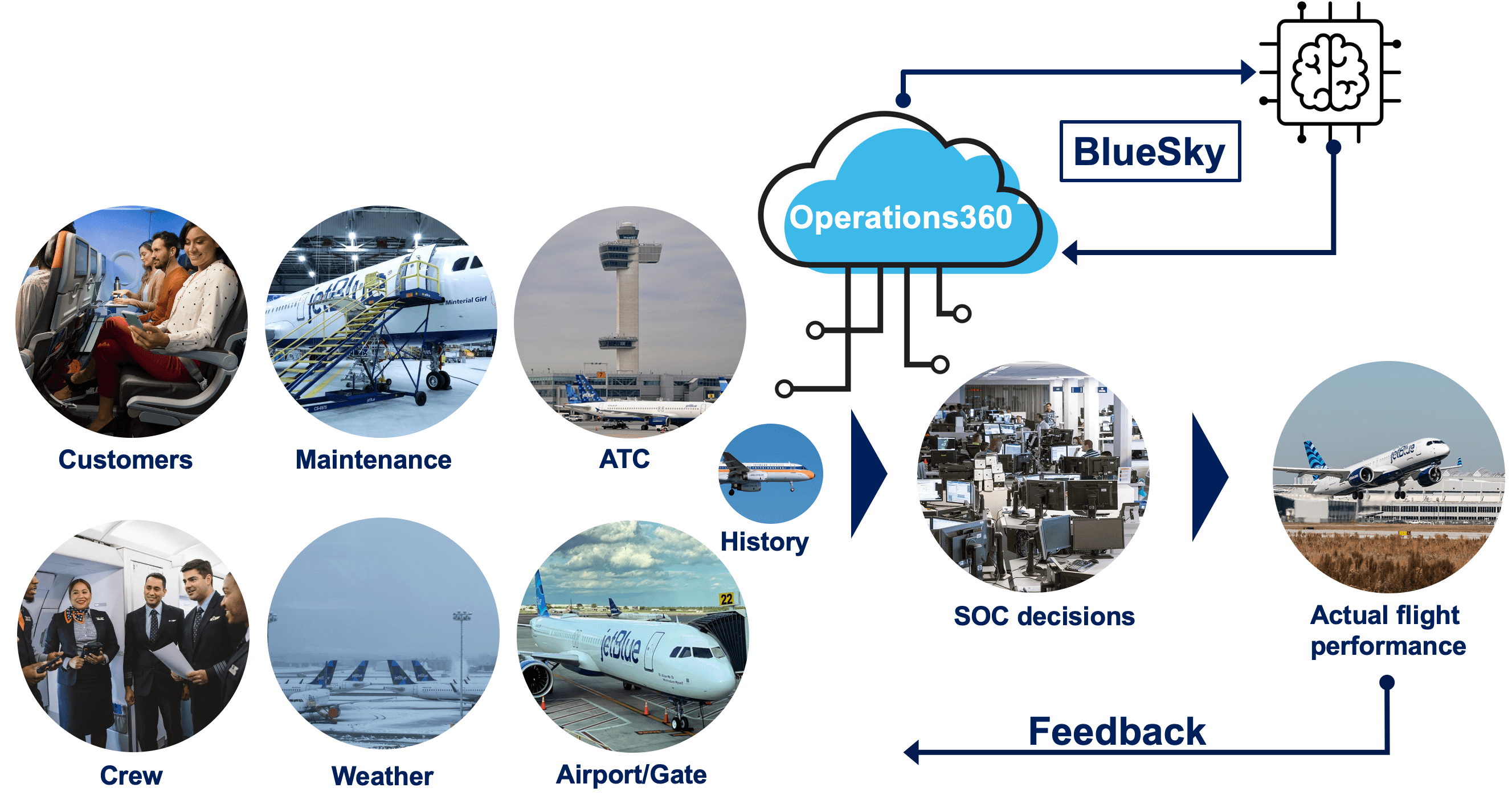
- Accelerating Innovation at JetBlue 🛫 Using Databricks: (
▶️ video) thanks to Databricks JetBlue has benefited with: Rapid prototyping, iteration, and launching of data pipelines, jobs, and ML models; Elevated customer experience; Continuous improvement of overall value; Lowered TCO - How Akamai Leverages Databricks Unity Catalog For Distributed Data Governance (accompanying Summit presentation and slides): with 50 exabytes of data accessed across 80 workspaces, Unity Catalog brought many efficiencies to the team:
- Eliminated the need for duplicating mounts for shared datasets across workspaces
- Implemented fine-grained access controls at the row and column levels
- Eliminated the pains of syncing user management and access control across multiple workspaces
- Single pane of glass for data observability
- Why we migrated to a Data Lakehouse on Delta Lake for T-Mobile Data Science and Analytics Team
- FactSet's Lakehouse adoption resulted in faster processing times and improved team productivity while reducing costs by 83%
- How Stack Overflow built their new course recommendations solution on Azure Databricks. I think it's safe to say we all owe Stack Overflow some thanks for aiding us in our technical careers; so I was happy to see Databricks play a role in helping the community discover relevant courses. "[It was] clear that leveraging one platform for as much as possible would be wise, and our platform of choice was Azure Databricks. This allowed us to keep all data processing, feature engineering, model versioning, serving, and orchestration all in one place."
- How Instacart Ads Modularized Data Pipelines With Lakehouse Architecture and Spark
- Ahold Delhaize: Workflows helps data teams scale and reduce costs: 1K daily ingestion jobs with 50% cost reduction
- Having your cake and eating it too: How Vizio built a next-generation data platform to enable BI reporting, real-time streaming, and AI/ML: Vizio's journey in adopting the Lakehouse for a single platform that met their data warehouse and ML needs. " Databricks was the only platform that could handle ETL, monitoring, orchestration, streaming, ML, and Data Governance on a single platform. Not only was Databricks SQL + Delta able to run queries faster on real-world data (in our analysis, Databricks was 3x faster) but we no longer needed to buy other services just to run the platform and add features in the future"
- Ripple: ML Training and Deployment Pipeline Using Databricks: how Ripple uses Databricks to manage robust MLOps pipelines across a multi-cloud (GCP and AWS) architecture: "ML flow tracking and MLflow API help coordinate these actions with ease in spite of using different platforms for model development, testing and deployment"