AutoTarget: A Disease-Associated Drug Target Recommendation System via Node2vec Representation Learning in PPI Networks
Target discovery, the initial stage of early drug development, is a critical and resource-intensive process. This is because an improper target selection can result in ineffective drug efficacy. As a result, pharmaceutical companies invest considerable time and resources to find the appropriate target at the outset. To address this challenge, we introduce AutoTarget, a disease-associated drug target recommendation system that uses node2vec with node classification and neighborhood context in protein-protein interaction networks. AutoTarget predicts drug targets structurally equivalent to existing drugs on the market by leveraging the premise that potential drug targets exhibit similar local structural and neighborhood context within PPI networks. With AutoTarget, researchers can quickly and easily obtain a list of novel drug targets related to a specific disease, streamlining their drug discovery process.
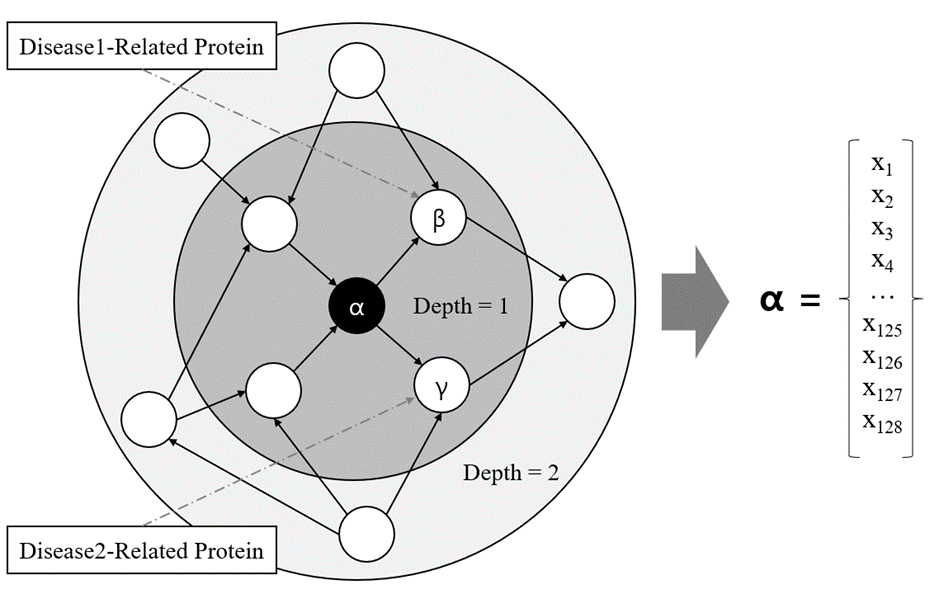
The above figure illustrates the process of embedding through the utilization of neighborhood context and structural equivalence between nodes. The node marked as α, depicted in black, serves as the central node, while the remaining nodes depicted in white, represent the neighborhood nodes. The vector representation of α can be derived based on the contextual information of its neighboring nodes at various depths. In this study, each node is represented as a 128-dimensional vector. β and γ are both connected to a single node at depth 1 and to two nodes at depth 2, with the directions of their edges being consistent. β and γ display similar connectivity patterns, and as a result, possess structural equivalence. If the protein β is associated with disease 1 and serves as a drug target, and the protein γ is linked to disease 2, this indicates that γ could serve as a novel potential drug target for disease 2. Furthermore, if a neighborhood context δ, similar to β, is identified in a pathway where the target for drug discovery is currently unknown, then δ can also be considered as a potential target.
Due to Github's upload capacity limit, you must download some datasets to reproduce model training.
1. Download STRING DB
- protein network data (full network, scored links between proteins)
- species: Homo sapiens
- https://stringdb-static.org/download/protein.links.v11.5/9606.protein.links.v11.5.txt.gz
- Convert to all.edgelist using 1. conversion jupyter notebook file.
2. Download Therapeutic Target Database(TTD)
- Target Information Downloads
- Download Uniprot IDs for successful targets only
- https://db.idrblab.net/ttd/sites/default/files/ttd_database/P2-02-TTD_uniprot_successful.txt
3. Conversion of identifiers using bioDBnet
- The TTD database from step 2 is used as input.
- Input: UniProt Entry name
- Output: Ensemble protein ID
- https://biodbnet-abcc.ncifcrf.gov/db/db2db.php
- This is the first input file of the autotarget Jupyter notebook file.
4. Node2Vec+
- Embedding each protein node of the STRING DB in step 1.
- https://github.com/krishnanlab/PecanPy
- ./pecanpy --input graph/all.edgelist --output demo/karate_n2vplus.emb --mode SparseOTF --extend
If you have any questions or suggestions, please contact us at hskong@snu.ac.kr.